Jak pisałem w jednym z moich postów ? Jak rozpoznać Pingwina 3.0?, ostatnia aktualizacja algorytmu Pingwin zadziwiła wielu webmasterów. Google nie tylko odświeżył algorytm Pingwina, ale także rozwinął aktualizacje Google Panda, Pirate Update i Thin Content prawie w tym samym czasie. Na pewno skomplikowało to sytuację przy diagnozowaniu spadków strony.
W tym artykule chciałbym skupić się na ?drugim odbiciu ? serwisu Algoroo.com ? Thin Content Update z 25 października 2014r.
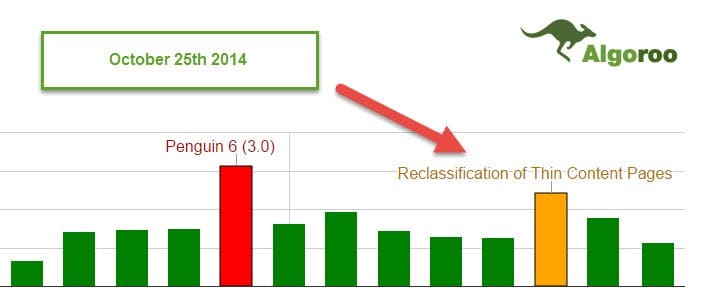
Zanim przejdę do tematu, chciałbym przypomnieć jedną ważną rzecz- zdecydowałem się napisać ten post głównie dlatego, że dotychczas widziałem zbyt wiele przypadków, gdzie błędnie zdiagnozowano spadki jako Penguin 3.0 (były to często inne problemy). Skupianie się tylko na linkach bez rozwiązywania problemów, które powodowały, że algorytm ? Thin Content? uderzył w waszą stronę jest zdecydowanie złym rozwiązaniem, które może zrujnować wasz biznes.
DejanPetrovic z DejanSEO zadał interesujące pytanie na Google Plus, które tylko potwierdziło moje odkrycia.
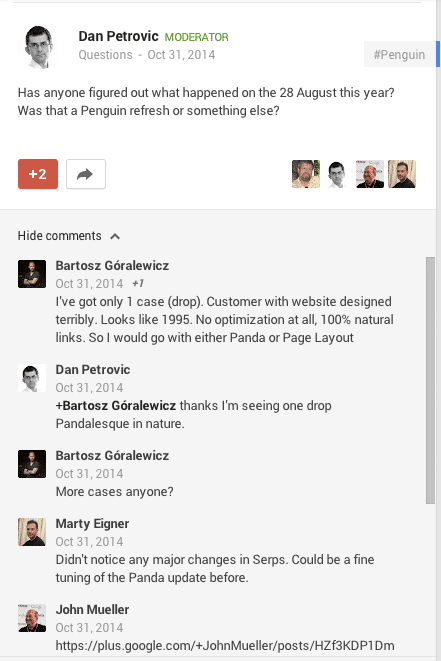
W tamtym czasie, miałem tylko jednego klienta, startup z problemem dotyczącym Thin Content, który skontaktował się ze mną ( to było tylko 4 ? 5 dni po tym, jak webmaster zauważył spadki). Przypuszczałem (jak możecie zobaczyć powyżej, że była to Panda lub Page Layout. Wówczas nie byłem świadom skali tej aktualizacji oraz tego , że targetowała problemy związane z tzw. Thin Content (strony z małą ilością unikalnych treści). Ciężko było wyciągać wnioski na podstawie jednej strony… do czasu ukazania się tego postu Dan?a Petrovic?a , którego zainspirowały odkrycia Martina Reed?a – rzucające światło na ten problem.
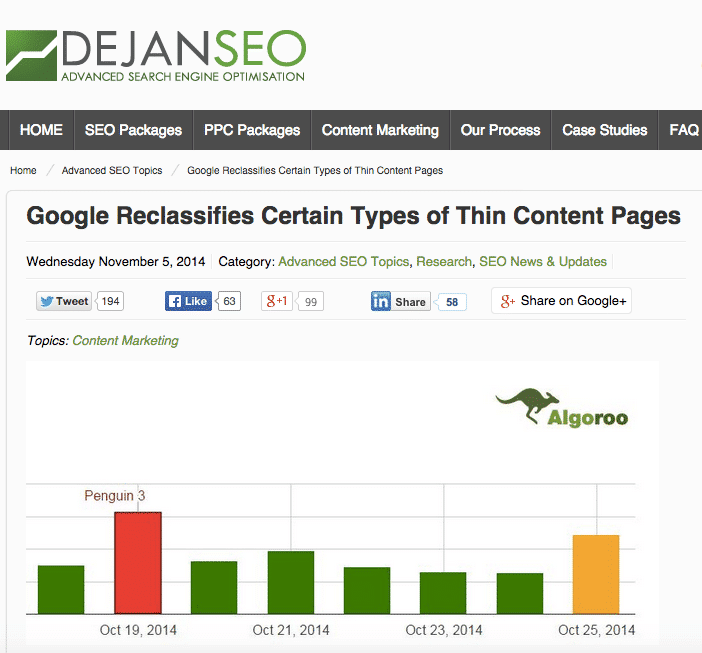
Podsumowując odkrycia z powyższego postu Martin?a: w zasadzie odkrył on interesujący przypadek podstron pokazywanych w Google Webmaster Tool?s jako soft 404.
Niestety działo się tak tylko w niektórych przypadkach. Ja nie spotkałem się z soft 404kami, mimo że niektóre strony, nad którymi pracuję to w 99% thin content.
Rozpoznawanie aktualizacji ?Thin Content? uderzającej w Twoje strony
Pomijając aktualizacje z 25 października warto sprawdzić kilka innych czynników.
stosunek treści do kodu HTML
powielona zawartość
problemy techniczne
Problemy z crawlowaniem domeny przez Google Bota
pętle przekierowań
błędne Sitemapy strony
?Spuchnięty? indeks
Dużo stron bez wartościowych treści
Brak alt tagów i przyjaznych nazw dla obrazków
Lista powyżej może wydawać się zbyt ogólna, w związku, z czym pozwól mi przedstawić kilka przykładów.
W ciągu kilku ostatnich dni miałem wielu klientów, którzy skontaktowali się ze mną, aby porozmawiać o aktualizacji z 25 października
Aktualizacja Thin Content, studium przypadku
Spotkałem się z kilkoma interesującymi przypadkami, ale chcę podzielić się jednym z najciekawszych, jak dotąd.
Znaczący przypadek w handlu internetowym (eCommerce)
Mały sklep internetowy z USA oferował najwyższy poziom usług, był bardzo dobrze znany wśród społeczności oraz miał naturalny profil linków. Od wielu lat (10+) na rynku, nigdy nie spadał w rankingach. Ruch brandowy, kierował więcej ruchu niż najpopularniejsze słowa kluczowe.
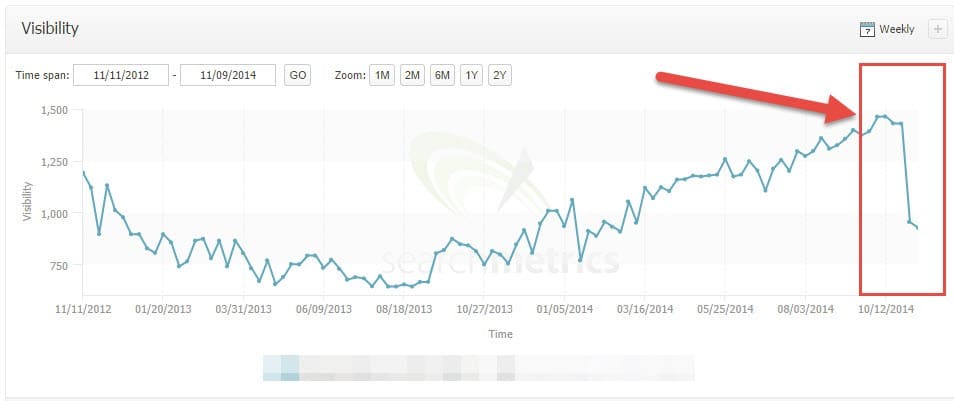
Główny problem:
- Bardzo skromny i techniczny opis produktów. Tylko kilka różnych słów na stronach produktów.
Wierzę, że Google spojrzy tylko na oryginalną zawartość danej strony i zignoruje jej szkielet (np. treści w menu powtarzające się na każdej podstronie).
Google według mnie ?docenia? tylko treści unikalne w obrębie domeny ignorując resztę.
To podejście (niezależnie od tego, czy jest dobre, czy złe) jest pomocne w diagnozowaniu problemów Thin Content dotykających sklepów internetowych.
Pozwólcie mi pokazać przykład produktu na stronie sklepu internetowego:
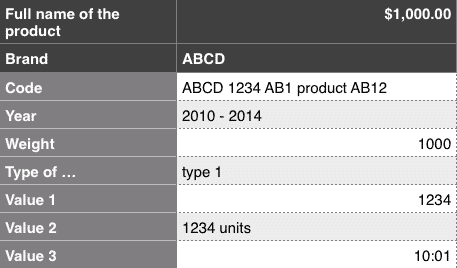
Cała zawartość po lewej stronie jest powielana na wszystkich stronach danej kategorii w tym sklepie. Strony rozróżnia nagłówek, cena i zawartość po prawej stronie (głównie cyfry i dane techniczne).
Jest to wystarczające dla użytkowników, którzy znają tę markę na tyle dobrze, aby dokonać zakupu. Jednakże, dla Google jest to niemalże definicja strony Thin Content.
- Brak podpisów pod obrazkami
W przypadku tej strony, zdjęcia były jedną z jej największych wartości. Tysiące unikalnych zdjęć WYSIWYG. Niestety, nie ma możliwości, aby Google dowiedziało się o zawartości tych obrazów.
Bez podpisów, pod złą nazwą (DSC_1234.jpg) Google nie jest w stanie rozpoznać, co jest na danym zdjęciu, przez co jest to tylko kolejny numer na stronie, który w ?oczach bota? nie dodaje wartości stronie.
- Niski stosunek tekstu do HTML
Nie ma magicznego współczynnika, a dla niektórych stron internetowych (w tym mojej) jest niezwykle trudno osiągnąć rezultat wyższy, niż 15%. W dalszym ciągu im więcej procent tym lepiej.
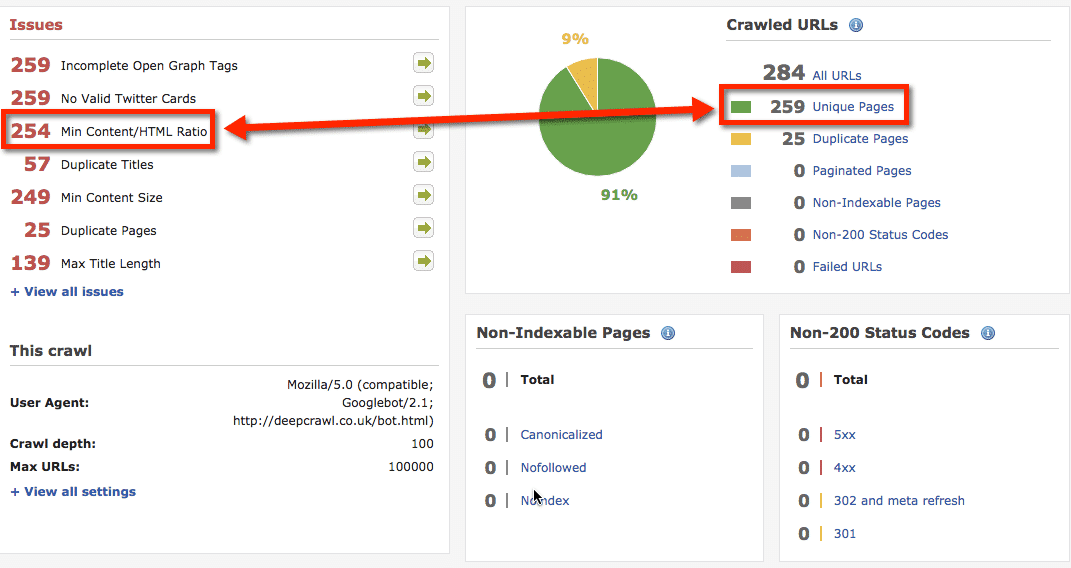
W przypadku tego konkretnego sklepu ten współczynnik był niezwykle niski (3 ? 5%). Przez co było to oczywistym problemem, który działał na Google jak szkło powiększające skierowane na problemy Thin Content.
Deep Crawl dobrze spisało się odnajdując problemy Thin Content.
Inne interesujące przykłady
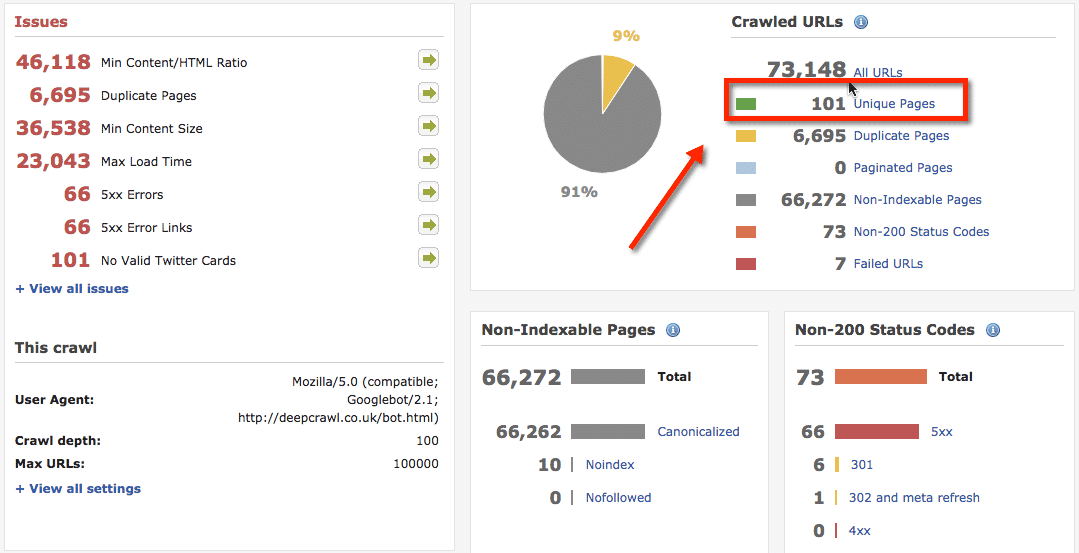
1. Mała strona Firmowa
Tylko 101 unikatowych stron generuje tysiące duplikatów i stron Thin Content ? dotarło to do mnie 25 Października 2014 roku.

Co jest bardzo interesujące w Google Webmaster Tools nie generują one błędu 404 ani nie powodują index bloat?u. Google po prostu nie indeksuje zduplikowanych stron, lecz ich istnienie wciąż ma negatywny wpływ na pozycje strony.
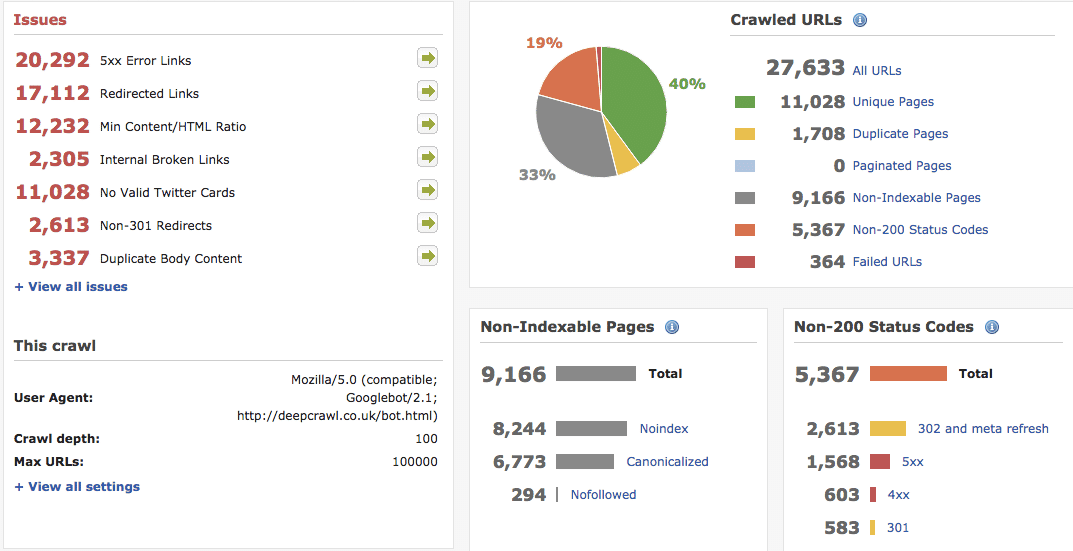
2. Sklep internetowy ? spadek z 25 października 2014 roku.

Chyba nie muszę komentować poniższego zrzutu ekranu z DeepCrawl. Jest to tylko ogólne spojrzenie na główne problemy, które wymagają rozwiązania.
Podsumowanie
Aktualizacja Thin Content wydaje się czyścić niedobitki po Pandzie. Na szczęście jest ona o wiele łatwiejsza do zdiagnozowania i naprawienia. W przypadku tej aktualizacji można polegać na jasnych danych technicznych( tekst/html, duplikaty wewnętrzne itd.) Są one łatwiejsze do zmierzenia niż user experience.
Kiedy Twoja strona może „dojść do siebie” po aktualizacji Thin Content?
Odpowiedź jest bardzo prosta! Nie wiemy dokładnie, ponieważ Google nigdy nie potwierdziło w żaden sposób tej aktualizacji, ani nawet nie trudziło się przekazać webmasterom informacji o możliwej sposobie na powrót na pozycje.
Jedyne, co mogę tutaj zrobić to wyrazić swoją opinię, poprzez tzw.?educated guess?. Według mnie, podobnie jak z ?Google Pandą?, musisz rozwiązać wszystkie problemy oraz być pewnym, że Google przeindeksuje/przecrawluje Twoją domenę, a odzyskać ruch możesz przy następnej aktualizacji ?Thin Content?
Jak rozwiązać problemy?
Wydaje mi się, że dla większości agencji SEO jasne jest, że podejście do tego problemu i priorytet wprowadzanych zmian jest obowiązkowy dla poprawy strony internetowej.
Mogę gorąco polecić Deep Crawl?a , ponieważ jest bardzo dobry w odnajdywaniu stron Thin Content. Niestety, aby sytuacja naszej strony poprawiła się, nie wystarczy polegać tylko na nim. Wymaga ona pełnego, wykonanego ręcznie audytu i sprawdzenia jak największej ilości treści ręcznie. W dalszym ciągu uważam, że ten problem jest względnie łatwy do naprawienia, w porównaniu do Page Layout update, czy aktualizacji Google Panda.
Jeżeli znasz jakieś interesujące przykłady, podziel się nimi poniżej w komentarzach. Z przyjemnością wysłucham o Twoich doświadczeniach z aktualizacją Thin Content!
Przeczytaj także: co to jest thin content?





Myślisz, że uzupełnienie contentu, który był już w witrynie i rozbudowanie go daje rezultaty w tym przypadku? Oczywiście mam na myśl witryny, które nie zostały ruszone na przestrzeni minionych powiedzmy 2 lat przez żadną aktualizację?
A tak na marginesie, od razu widać że to nie Zgreda tekst. Przestraszył się chyba tej aktualizacji na poważnie 😉
Tak na marginesie autor się podpisał 🙂
Ja osobiście mieszam i zmieniam tekst, wydłużam je (nigdy skracam) – i daje to jakieś rezultaty ale nie są to topy 🙂
Podpisał się na końcu. Ja po kilku akapitach uniosłem prawą brew 🙂
Mam przypadek dwóch witryn które leczę z tego update. W obu postawiłem na redagowanie treści, dodawanie jej tam gdzie jej nie było i wyindeksowanie najmniej potrzebnych/wartościowych stron. I tak się zastanawiam, czy pomóc im trochę linkowaniem dobrej jakości czy z czystej ciekawości zobaczyć co się z nimi stanie.
Na chłopski rozum, nawet zmniejszenie site (o mało wartościowe strony- i nie mówię tylko o jakichś archiwach, ale zwykłych „stronach” lub „postach”) powinno pomóc, bo wskaźnik jakości idzie w górę. Jeżeli do tego dodać przeredagowanie treści i nasycenie jej w informacje dodatkowe to serwis szybko powinien wrócić tam gdzie jego miejsce.
Co do altów bym się spierał 😉
Google znacznie chętniej oznacza zdjęcia na podstawie innych czynników.
Drugi sklep 25 października? przecież wtedy była ogólna Panda..
Kazdy właśnie tak sadzi ze to była ogólna Panda, a potem jest ból..
Możesz napisać coś więcej o tym, co Google może bardziej interesować w obrazkach?
Czy Nazwa pliku? Title? Alt? mają wg Ciebie mniejsze, większe znaczenie?
Nazwa pliku + alt. IMHO te 2 rzeczy sa podstawowe i musza byc jasno czytelne dla Google bota.
Na pewno oprócz opisów w altach i samej nazwy pliku, google też opiera się na mechanizmie diagnozy zawartości obrazka. Na pewno nie jest to podstawowe kryterium ale zauważyłem u kolegi, że jakaś md5 z obrazka jest liczona nawet gdy zmiana titla jest wprowadzona.
No i już od dłuższego czasu się o tym mówi i na pewno jest to super ważne aby content się rozwijał. Najtrudniej będzie sklepom bo trudno jest zrobić tam unikalne opisy…
ad1 stosunek treści do kodu HTML – nie ma żadnego wpływu na nałożenie kary.
ad2 powielona zawartość – kluczowa rzecz,
ad3 problemy techniczne – istotny punkt, lecz kary tego typu nie wynikają bezpośrednio z problemów technicznych witryny, tylko ogólnej sytuacji – musi nałożyć się kilka czynników, żeby kara przeszła.
ad4 Problemy z crawlowaniem domeny przez Google Bota – zazwyczaj dotyczy patrz punkt trzeci
ad5 pętle przekierowań – łatwe do zdiagnozowania i naprawy,
ad6 błędne Sitemapy strony – sitemapa na spadki nie ma żadnego wpływu,
ad7 i ad8 ?Spuchnięty? indeks oraz Dużo stron bez wartościowych treści – poniekąd to jest jedno zagadnienie – czyli powielanie treści punkt 2.
ad9 Brak alt tagów i przyjaznych nazw dla obrazków – brak altów nie ma najmniejszego związku z nałożeniem kary, za to przeoptymalizowanie już tak.
Jak mamy byc juz techiniczni to:
Wymienilem czynniki WARTE sprawdzenia. Daleki mi rzucac tym, co dokladnie jest brane przez Google pod uwage przy tym algo, a co nie, to wie kilka osob na swiecie pewnie tylko, ja niestety nie jestem jedna z nich (Ty też).
ad1 –
a) Update/zmiana lub wypuszczenie nowego algorytmu to nie kara (wg Google) wiec trzymajmy sie terminow.
b) Wymienilem czynniki wspolne stron, ktore spadly. Czy to jest czynnik, czy nie nie odwazylbym sie mowic ze na 100% nie (lub tak). Nie wiemy tego, a warto zauwazyc wspolne problemy.
ad3 – Znowu – nie bylo zadnej kary. Reszty nie rozumiem. Napisalem, ze jest to czynnik wart sprawdzenia. Podtrzymuje – warto to sprawdzic przy stronach dotknietych Thin Content
ad6 – Skad to wiesz?
ad7/8 – caly ten artykul moglby brzmiec „problemy techniczne” wg tego co mowisz 🙂
ad9 – a) kary nie bylo b) Nie wiesz tego (ja też nie). Ja zauwazam wspolne problemy ukaranych stron, nie twierdze ze WIEM co dokladnie bylo targetowane. Takie stwierdzenia ze cos JEST na 100% lub nie jest na 100% to wprowadzanie ludzi w błąd Mariuszu.
No tak Bartku, tak samo jak w Twoim podobno zrobionym audycie dla mierzymy.pl widziałem już próbkę Twoich umiejętności a raczej ich brak, więc z łaski swojej nie zarzucaj mi, że się nie znam na rzeczy, bo gdybyś zrobił w styczniu 2014 to co do Ciebie należało, sklep mierzymy nigdy nie dostałby filtra w Google, przynajmniej nie za duplikowanie.
Wracając do tematu, zrobiłem sporo analiz, wiadomo że każdy przypadek jest inny ale ewidentnie widoczne są części wspólne i mogę z całą odpowiedzialnością powiedzieć, że część rzeczy które wymieniłeś jako „do sprawdzenia” nie ma wpływu na nałożenie kary ale jak to mówią, to że dziś jest okej, nie znaczy że jutro będzie tak samo. Algorytm podlega ciągłym zmianom i to co wczoraj nie było uwzględniane, jutro może być. Pozdrawiam!
Co do Twojego hejta – strona nie spadła po moim audycie czy przeze mnie 🙂 Polecam kontakt z właścicielem 🙂 Zajebisty facet i do dzisiaj mam z nim bardzo dobry kontakt. Jednak trochę racji masz, dałem d… z komunikacją i za to Marka przeprosiłem i temat wyprostowalem. Publicznie i chętnie przyjmuję to na klatę.
BTW, dalej mowisz o karze… 😀
Jak jest kara musi być i wina… nic samo z powietrza nie bierze się.
To nie jest hejt tylko czysty fakt, nie zamierzam tematu drążyć, to jest Twoja sprawa, tylko zarzucając komuś niewiedzę wpierw na siebie spójrz.
Zbrodnia i Kara… 🙂
Sorki za małą złośliwosc – z kazdym postem wrzucasz inna podstrone jako link z komentarza, site masz 364 wiec jesli dobrze mysle to 361 jeszcze zostalo…
Teraz rozumiem skad te dyskusje! 🙂
A tak na serio – nie podwazalem Twojej wiedzy i nie mam zamiaru – tak 100% szczerze – mysle ze na SEO sie znasz.
Wątek niniejszym kończe (ze swojej strony), bo szkoda mi czasu na przepychanki 🙂 Wysokich pozycji!
Ty masz inne doświadczenia, ja mam inne – różnica zdań jest nieunikniona i zdziwiłbym się gdyby było inaczej. Pewnie gdybyśmy razem pracowali i połączyli siły, nie byłoby filtra, którego nie dałoby się zdjąć, bo jak to mówią co dwie głowy to nie jedna, a co dwie to nie trzy. I to tyle w tej materii… Pozdrawiam Bartoszu!
Bartosz – to wyjaśniło mi się skąd w GWT mam setki 404 dla podstron które nie wyrzucają 404 a są jedynie podstronami z kategorii nie zawierających żadnych pozycji.Głowiłem się nad tym od jakiegoś czasu 😉
My na początku października zrobiliśmy gruntowny referesh na stronie blogowej klienta, która była kiedyś tworzona według założeń lepszych precli. Artykuły zostały wzbogacone o 100% treści, ale nie dodawaliśmy nowych artykułów, po prostu z artykułów na 1000-1500 znaków zrobiliśmy artykuły na 2000-3000 znaków. Ruch na blogu wzrósł 4-krotnie dzięki źródle wejść z organika, a ruch na stronie firmowej 2,5 razy. Aż taki dobry wynik nas pozytywnie zaskoczył. Jesteśmy w trakcie wdrażania tej strategii w kolejnych projektach. W związku z tym też mój cykl artykułów na blog.memtor.pl. Pozdrawiam autora i wydawcę:)
Mariusz, Bartosz – bo wywołany jestem do tablicy 😉
Moja współpraca z Bartoszem w zakresie mierzymy.pl dotyczyła trochę innych zagadnień. Duplikowanie treści następowało stale od dobrych 5 lat, a jedyne, co można zarzucić Bartoszowi, to przeoczenie tego problemu. Chociaż w naszych rozmowach nie padło z mojej strony zlecenie na audyt. Skupialiśmy się całkowicie na czym innym.
I absolutnie nie obwiniam Bartosza za filtr, który złapało mierzymy.pl. Późniejsze drobne niejasności wynikły raczej z błędów komunikacji i używanych sformułowań 😉 Bartosz zachował się jednak jak profesjonalista, wziął na klatę winę za niedomówienia i wspomógł mnie później w ramach „moralnej rekompensaty” kilkoma radami i informacjami. Dziękuję. Do dziś wymieniamy się mailowo spostrzeżeniami na różne tematy i to raczej ja jestem tutaj „pasożytem” 😉
Mariusz, Twoja rola w odfiltrowaniu mojej strony była niebagatelna, za co Ci już nie raz dziękowałem. Zważ jednak, że miałeś ułatwioną sytuację, bo pacjent był już chory 🙂 Niemniej bez Twoich wskazówek zapewne strona jeszcze tkwiłaby w filtrze 😉
Jako strona w tej dyskusji – APELUJĘ – skończcie temat mierzymy.pl i związane z moją stroną osobiste wycieczki 😉 Chętnie poczytam merytoryczne wypowiedzi. Szkoda naszego czasu na rozgrzebywanie brudów i udowadnianie sobie „kto ma większego” 😉
pozdro,
mp
Tyle już tych aktualizacji algorytmu Google’a dotyczących jakości contentu, że człowiek przestaje na to zwracać uwagę…
Czy nie mączą was już te ciągłe zmiany? Pewnie jeszcze będziemy pracować do 70. Komu starczy chęci na tą permanentną naukę?
Taki urok 🙂